Focusing on the frequently used features allows you to ship your product sooner, beating your competition on time to market.
Eliminating never used features also eliminates designing, testing, and deploying them, saving significant time and budget.
We deliver custom software solutions your users and your bosses will both love. Our S.N.A.P. agile methodology makes development flexible, fast, and virtually risk-free.

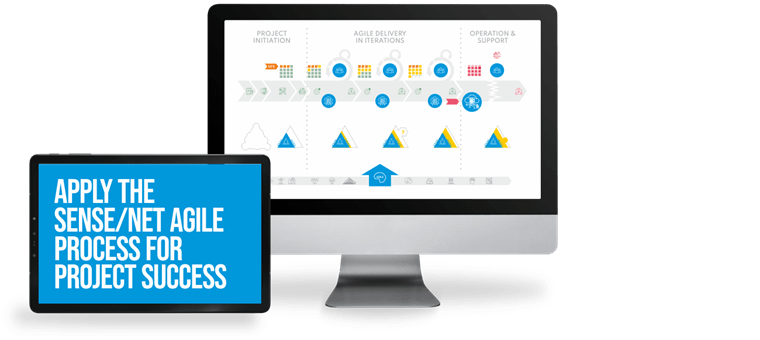

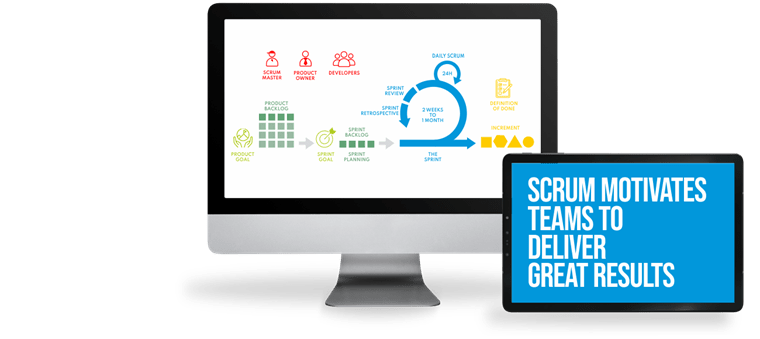
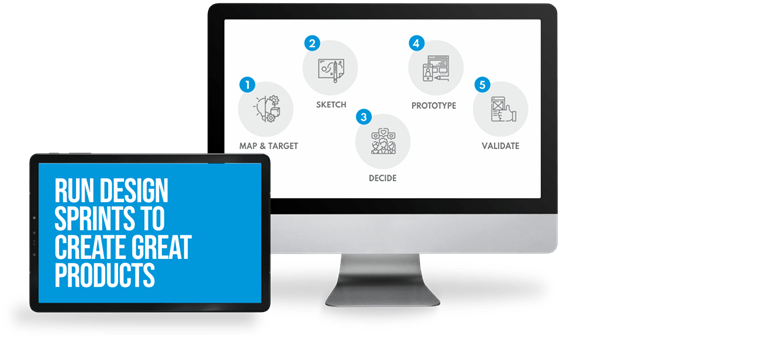


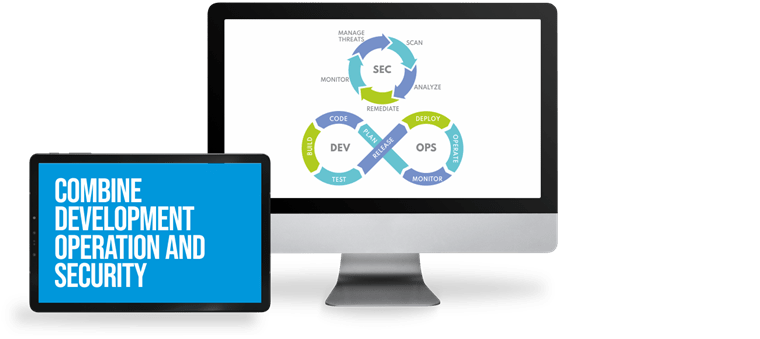


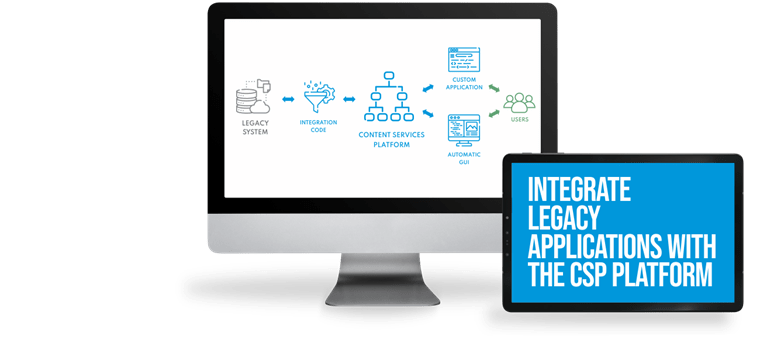

The Sense/Net Agile Process or S.N.A.P. gives you digital solutions with a short time to market, high product-market fit and superb ROI. See how the elements S.N.A.P. together.
By combining our Content Services Platform with our Managed Cloud, our Agile Teams can deliver high-quality Custom Software Solutions in short time frames on reasonable budgets, relying on the Sense/Net Agile Process or S.N.A.P.

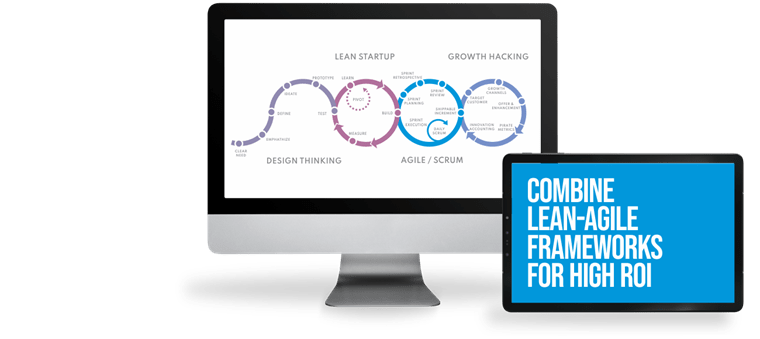
Excellent user experience, high quality, and rapid development are ensured by agile practices, such as working in Scrums, using Design Thinking, Design Sprints, building MVPs, Lean Thinking, Gemba Walks, DevSecOps, and more. Our teams are prepared for agile practices by one of our founders, who has trained thousands of people in agility.
Custom Software Solutions
We build our solutions on a proven platform with the S.N.A.P. methodology we have mastered over the years. The platform provides numerous services that most software projects or products require, such as search or permissions. This ensures a short time to market and high quality because the most demanding parts of coding are already in place and have been tested with many customers.
Content Services Platform
We save time by installing your solutions directly to our managed cloud platform instead of losing time and money by waiting for hardware, installation, and bureaucracy. Our scalable cloud infrastructure and associated services fit the needs of SMBs and enterprise customers. In addition, our private cloud and on-premise solutions deliver the privacy our most demanding customers require.
Managed CloudWe empower you to deliver successful digital solutions, whether you outsource or develop your solutions in-house. You can rely on our microservices platform to speed delivery and boost quality. You can build on our cloud infrastructure and agile teams. All with methodological support from our digital-agile experts.

Outsourcing your development to our agile DevSecOps teams saves time and allows you to focus on your business.
Custom Software Solutions
Outsourcing operations saves you the burden of owning and continuously upgrading hardware while outsourcing scalability and security risks.
Managed Cloud
Building your solutions on our microservice-based Content Services Platform saves considerable time and costs while providing high-quality solutions using already-tested code.
Content Services Platform
Rely on our digitalization and agile experts for methodological support in your projects or transform your organization with their guidance.
Agile AcademyWe understand that deadlines are vital for you. We have the methodological background, software, and infrastructure that allows us to keep deadlines.

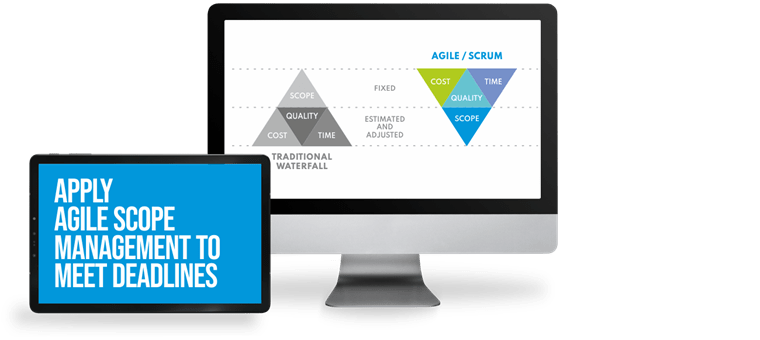
Our agile mindset and practices allow us to keep deadlines by closely cooperating with your business experts on managing the ever-changing scope.

We use a Continuous Integration and Continuous Deployment process so you can monitor progress, run user acceptance tests and give feedback in short timeframes.

By setting clear and measurable objectives for each project, we ensure your product meets those requirements in time.

By applying Service Design principles, we can ensure functionality will fit users' needs while also fitting the deadline.
By managing NFRs in time, we can avoid the common problem of facing scaling, performance, usability and many other issues after deployment.
Garbage In-Garbage Out refers to getting poor results from poor requirements. Therefore, we focus on collecting high-quality requirements to avoid this scenario.
By integrating a software product's development and operation aspects, we can launch the product faster without post-launch extra bug fixing and tuning.
By building on our robust and scalable Content Service Platform, we can avoid reinventing the wheel and focus on your business problems.
Don’t spend more than absolutely necessary. Research shows that most digital products are bloated with features users rarely or never use. Our agile and service design specialists can assist in finding and eliminating such features to save time and budget for more valuable functionality.

Focusing on the frequently used features allows you to ship your product sooner, beating your competition on time to market.
Eliminating never used features also eliminates designing, testing, and deploying them, saving significant time and budget.
Research shows that almost two-thirds of digital projects face crippling issues. We provide agile methodological support and a powerful platform, so your projects fall into the successful one-third.

We minimize project risk by providing total transparency about the ongoing development. You can track progress almost every day and have the opportunity to give feedback bi-weekly.
We build most of our solutions on our Content Services Platform, relying on proven code tested by hundreds of customers for years. This reduces quality-related issues significantly.
By building on our Content Service Platform, we avoid reinventing the wheel, so we can better focus on your business problems. We have completed hundreds of projects on this platform, so we have unmatched proficiency and delivery speed.

Build integrated systems with our platform’s
microservice architecture and open API and rely on services such as powerful search, permissions, and straightforward content modeling.

By modeling business entities as content
developers can rely on the built-in services of the platform that would otherwise take years to develop and test.
We avoid all common pitfalls associated with launching a new custom software solution using the proven Content Service Platform and our S.N.A.P. methodology.
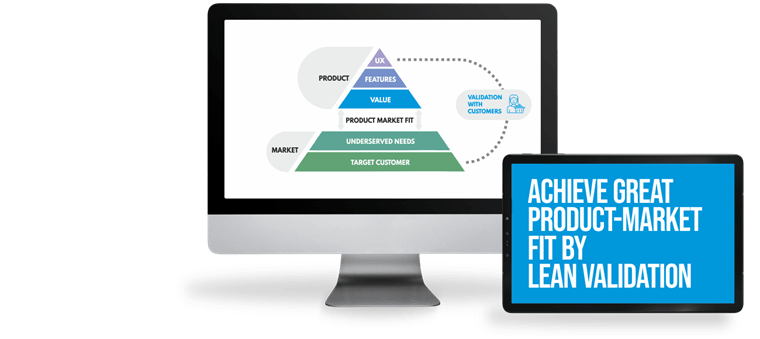
Unlike deadlines, time to market is different. It’s the art of creating a competitive product in a minimum time, with compromises smartly chosen. Focusing on the right requirements and managing scope with agile scope management, delivery will be faster, continuous and yield better results.

Our agile mindset and practices allow us to keep deadlines by closely cooperating with your business experts to manage the ever-changing scope.

The Minimum Viable Product mindset proves helpful when launching a new product in a short time frame. We build the product incrementally, frequently testing with users.
By managing the scope smarter, we can save resources, conduct research with users and design better user experiences. Faster lean validation leads to better product-market fit. Agile methodologies allow us to react to changes more quickly.

Thanks to the S.N.A.P. methodology, millions of users enjoy our platform and custom software solutions worldwide, benefiting companies of many sizes and industries.


Our digital solutions are built by digital natives who strive for excellence and have a passion for supporting digitalization. Customer happiness is no cliché for us. We have 25+ years of agile delivery experience from hundreds of projects. Our culture is purpose and values-driven, our strategy is managed in an agile way with OKRs.

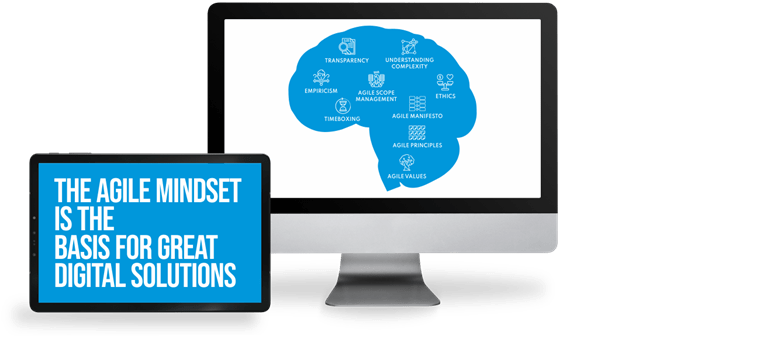
The shift towards Agile methodologies in project management and software development is more than just a procedural change; it represents a profound transformation in workplace culture and individual mindset. This journey, while promising enhanced flexibility, efficiency, and collaboration, is often fraught with challenges, rooted deeply in the human psyche's resistance to change. Understanding these challenges is crucial for organizations aiming to truly embody Agile principles.

In the ever-evolving landscape of technology, the question looms large: Will AI or artificial intelligence replace software developers? The notion itself sparks a plethora of debates across the tech community. After all, programming has traditionally been about instructing machines on what to do, albeit through a specialized language. Yet, the future hints at a possibility where instructions could be given in plain English, or even Hungarian, for that matter. But does that fundamentally alter...

As someone who's navigated the waters of both small IT companies and multinational giants, I've witnessed firsthand the disparities in how they operate and serve their customers. It's become increasingly clear to me that when it comes to delivering exceptional service, innovating rapidly, and staying agile in an ever-evolving tech landscape, small IT companies have a significant edge over their larger counterparts. Let’s see why.

During my experience teaching Scrum courses, I often encounter a recurring question: how can we foster harmony and collaboration between junior and senior team members in a team of peers, where every member is equal? In this blog post, we will explore the importance of facilitating a healthy debate between junior and senior members, emphasizing the agile values of openness, respect, and courage. By nurturing a culture that encourages mutual respect and fosters open dialogue, teams can leverage...

In the realm of business software production, the quest for creating accurate and effective specifications is a perpetual challenge. To tackle this, software development teams have turned to a powerful technique called Gemba walks. Originating from the Japanese term "Gemba" meaning "the real place” or “crime scene”, this approach involves going to the actual location where work is performed to gather firsthand knowledge and insights. In this blog post, we will explore the significance of Gemba...
Sense/Net was founded by enthusiastic programmers who wanted to turn their passion into a career. All founders and directors have IT and agile backgrounds, so they understand your challenges and lead teams of like-minded professionals to meet your requirements and needs.

Sandor Kiss
co-founder of
Barion & Sense/Net

Norbert Voros
director
ESOP shareholder

Thomas Biro
director, chairman
co-founder of
Barion & Sense/Net
We cannot wait to start your next digital project or product. So book an appointment and talk to senior IT experts instead of your typical salesperson.





 The website includes cookies
The website includes cookies